通用網站內容爬蟲抓取工具,可批量抓取任意站點的小說、論壇內容等並保存為TXT文檔




起點等都推薦用這個腳本【小說】下載腳本,遇到沒人願意適配的小站再考慮我的腳本。
勿用于版權站,如造成侵權或對象站點損失,後果自負。
輕量級抓取腳本,用於下載網頁小説或其他文字內容,理論上通用於任何靜態寫入正文的小說網站、論壇、貼吧等而無需規則。
腳本會自動檢索頁面中的主要內容並下載(省得複製完gal攻略還要手動逐條刪除「某某某13級頭銜水龍王發表於X年X月X日來自XX客戶端」)。
如果位於小說目錄頁會遍歷所有章節並排序拼接後存為TXT文檔。
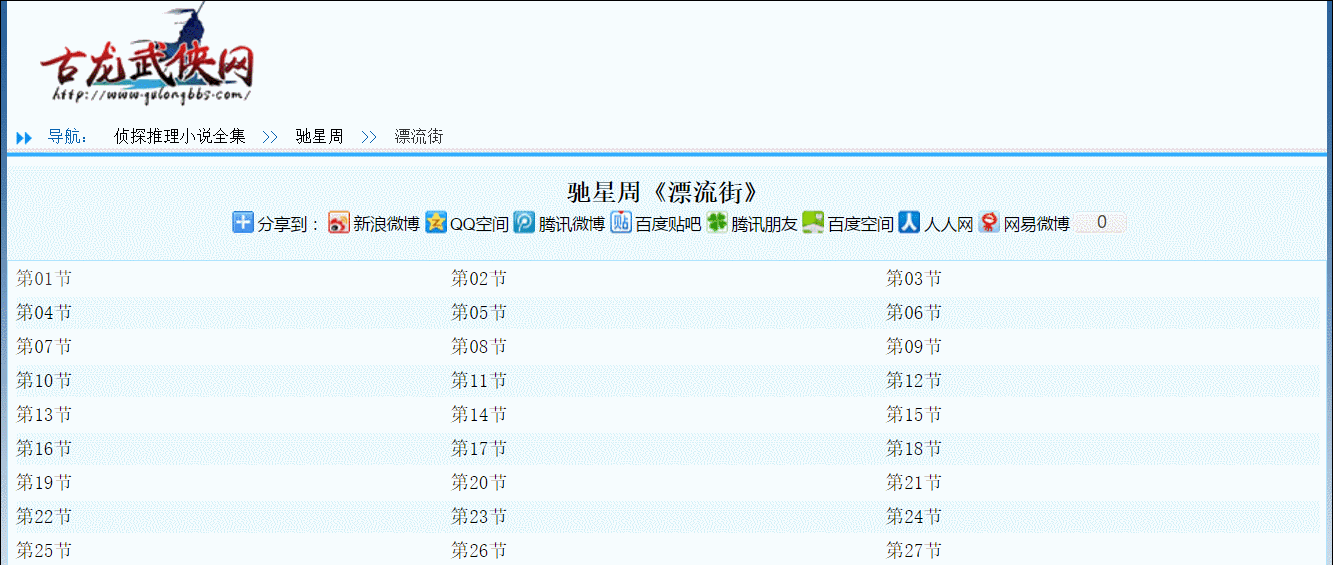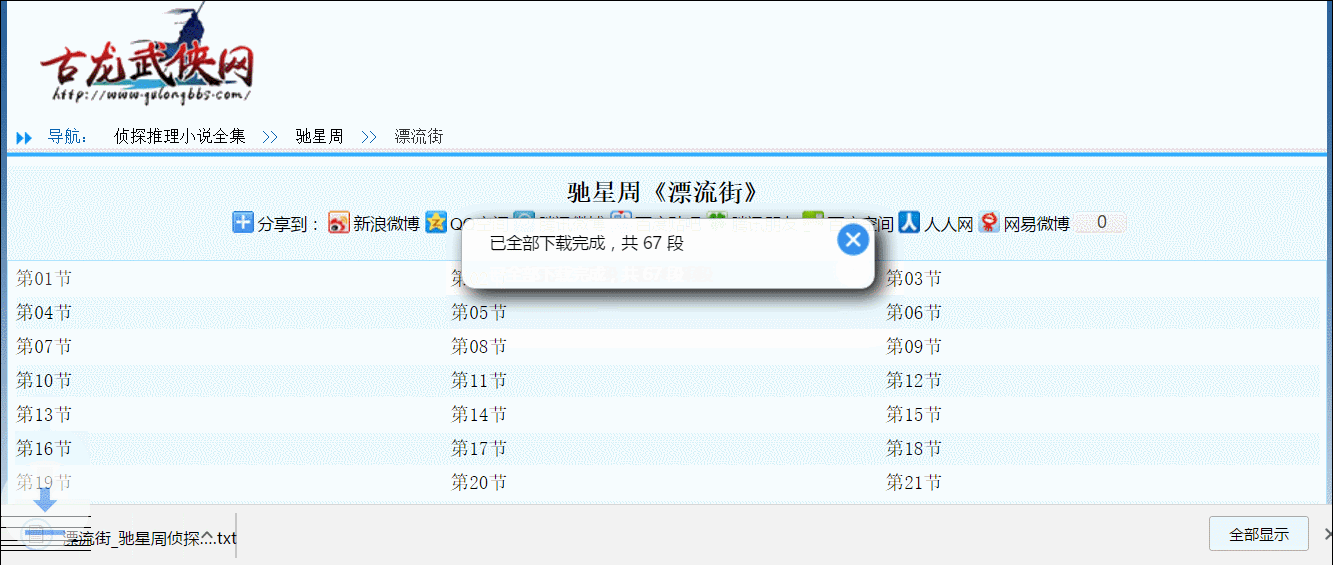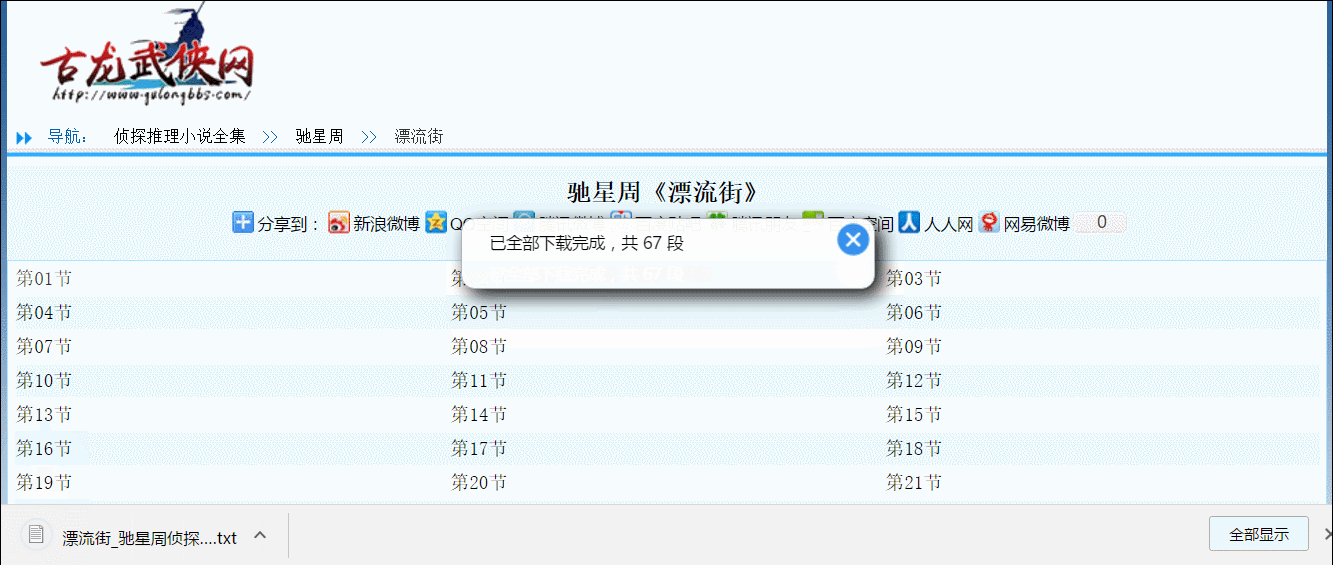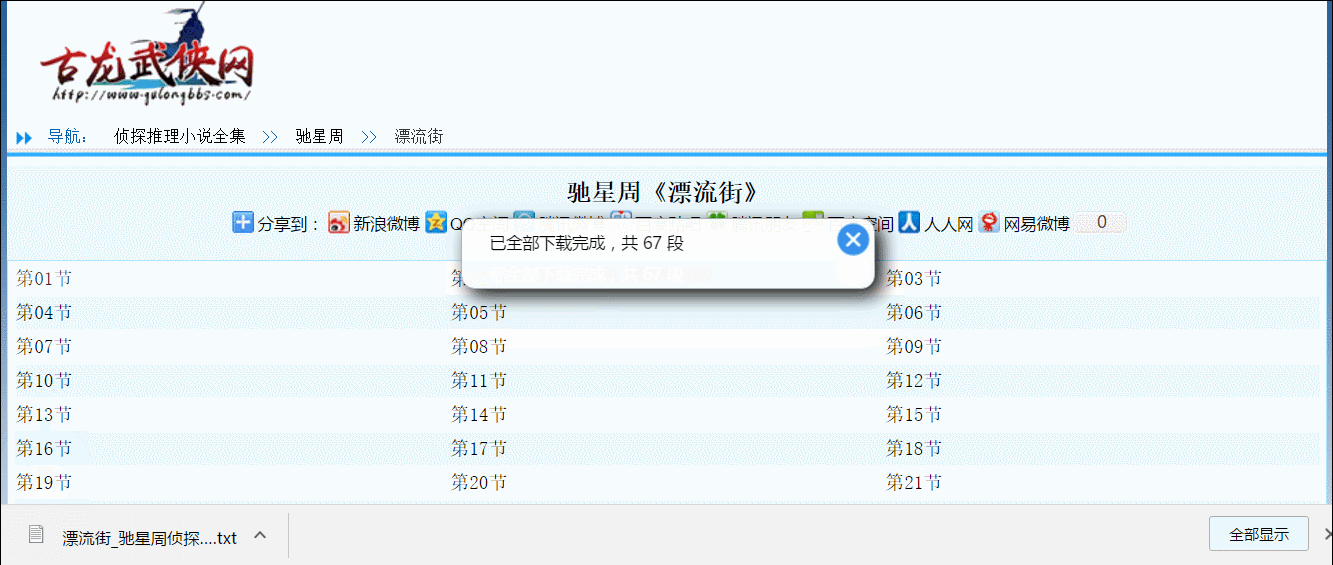
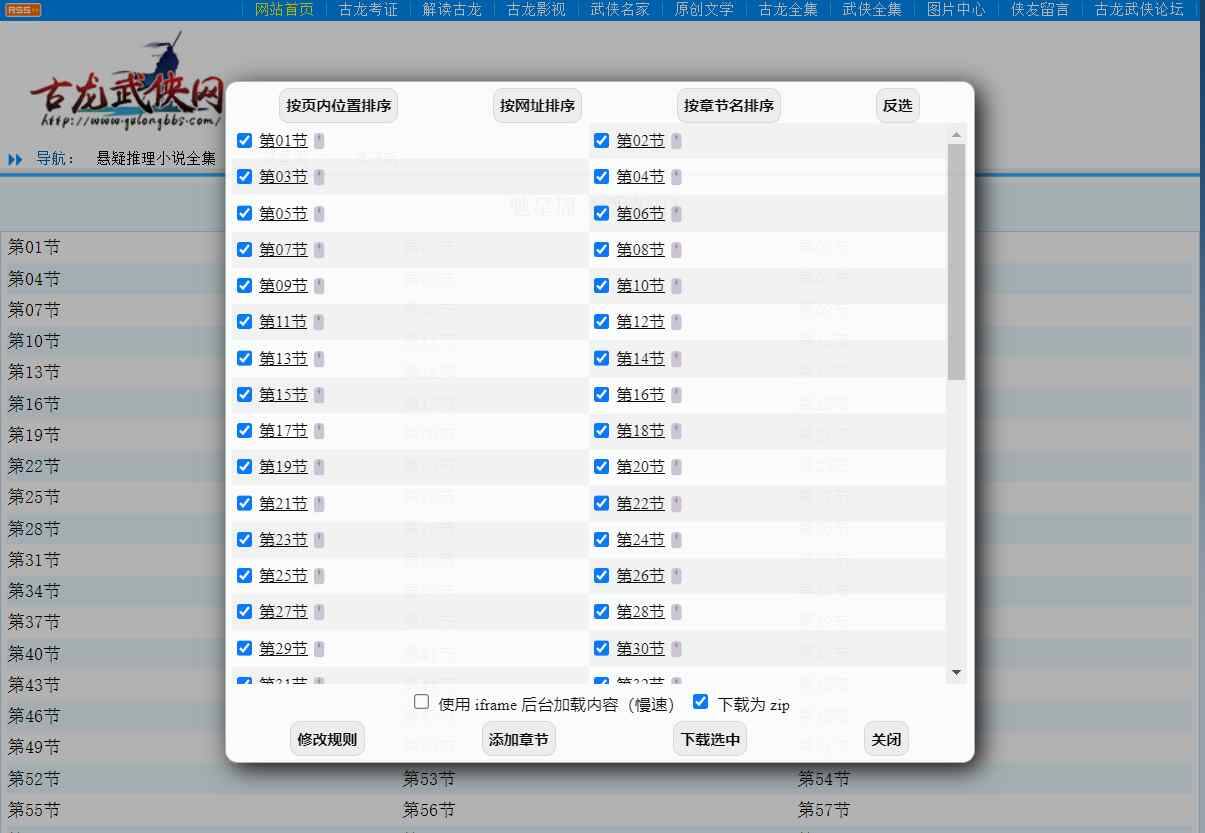
CTRL + F9 或點擊命令菜單SHIFT + CTRL + F9 忽略目錄,僅下載當前頁提交issue至Github(☑️已適配站點規則在下面【簡易自定義例子】處,自行複製取用)
亦可加入Discord群組尋求幫助。
怠惰小説下載器 ZIP 擴充 下載時分章節保存 TXT 並打包為 ZIP
❤️恰好對你有幫助的話,可透過PayPal.Me 或 Ko-fi请我喝一杯奶茶

此功共有七層,以第一層最易,第七層最難。
CTRL+F9 就完事了唄。
倘若章節鏈接沒有xx章、xx節、xx話之類的特徵字樣,可點擊腳本管理器命令菜單裡的自定義下載,輸入其中隨便一個章節名包含的字眼。
例如 “第1頁”,即可標記所有同級鏈接為目錄章節並下載。
假如頁面有兩套章節格式,也可標記多個,例如“眾神的風車,風車的眾神”。
亦可標記排除項,例如“眾神的風車01!02!03,風車的眾神!鐵幕”,代表標記“眾神的風車01”同級鏈接並排除含有 02 的項和含有 03 的項,同時標記“風車的眾神”同級鏈接並排除含有“鐵幕”的項。
如果內頁沒有正文,但章節鏈接與真實內容鏈接有關聯,可通過自定義下載,替換鏈接內容獲取真實內容。
例如 【眾神的風車@@articles*@@*articlescontent】,即可替換章節 URL 中的 articles 為 articlescontent 並自動獲取內容。
如果鏈接無法由直接替換得到最終地址,可用正則替換。
例如【眾神的風車@@articles(\d+)@@articlescontent_$1b】,即可替換章節 URL 中的 articles1、articles2 為
articlescontent_1b、articlescontent_2b
輸入章節的 css 選擇器可以更精確地標記章節鏈接。
例如.l_chaptname>a,代表 class 為 l_chaptname 的元素下的 a 鏈接。
可使用>>管道來處理抓取到的item。
下載內容可能含有乾擾碼,此時只需點擊懶人小說下載設置,輸入乾擾碼的 css 選擇器即可排除乾擾碼。
例如 .mask,.ksam,font.jammer,代表刪除 class 為 mask 或者 ksam 的元素或者 class 為 jammer 的 font 元素。
倘若正文不在內頁正文,是頁面加載後處理得到的,可點擊自定義下載,輸入自定義代碼對內頁進行分析獲取正確結果。
例如 【眾神的風車@@@@@@var noval=JSON.parse(data.querySelector("#meta-preload-data").content).novel;noval[Object.keys(noval)[0]].content;】,即可通過自定義代碼處理返回頁面獲取內容。
代碼中使用 data 可以獲得返回頁面的 document,最後一個表達式的值為最終寫入的內容。
如果返回 false,代表異步回調,可自行抓取內容並等待抓取成功後用 cb(content) 返回抓取到的 content。
倘若章節沒有鏈接,點擊後方才生成鏈接跳轉,可通過 >> 管道處理抓取到的元素生成章節鏈接,詳情見下方例子。
倘若正文已經經過加密,需要解密才能獲取正確內容,可打開瀏覽器的控制台,自定義 dacProcess 函數,調取頁面中網站自身的解密代碼處理抓取的加密數據。
例如控制台輸入dacProcess=data=>{return decrypt(xxx);} 代表調用網站的 decrypt 解密章節頁面返回的數據。然後再點擊自定義下載,需要注意自定義下載時標記章節是必需的。
某個章節名/CSS選擇器【選擇器後可跟>>傳入item添加處理代碼】 @@ 抓取到鏈接的正則匹配 @@ 對應匹配生成替換URL @@ 根據爬取返回內容data處理並返回最終文本
僅作為示例,如果網站改版導致失效,可自行摸索修改
.l_chaptname>a@@articles@@articlescontent如果需要下載已購買的VIP章節,用這個規則
a.btn_L_blue>>let a=document.createElement("a");a.innerText=item.parentNode.parentNode.querySelector('.l_chaptname').innerText;a.href=item.href;return a;@@articles@@articlescontent
main>section ul>li>div>a@@@@@@var noval=JSON.parse(data.querySelector("#meta-preload-data").content).novel;noval[Object.keys(noval)[0]].content;
-2代表每隔2秒下載一章主要是 因為我要下載馳星周的漂流街,卻發現前人的輪子「【小說】下載腳本」不能用,又不想為這破站 🙃 寫規則,而且
因為我要下載馳星周的漂流街,卻發現前人的輪子「【小說】下載腳本」不能用,又不想為這破站 🙃 寫規則,而且我就是看不上霸道總裁修仙穿越你咬我啊指不定它三天兩頭改個版呢。寫個通用規則的腳本,一來可以不用追著數不清的小說站適配修改更新,二來也免去了法律風險。
這個腳本會自動去查找主要內容並下載,不需要寫規則。當然如果你家網站廣告內容比正文還多我也沒辦法。
遇到特殊網站還是建議用「【小說】下載腳本」。



