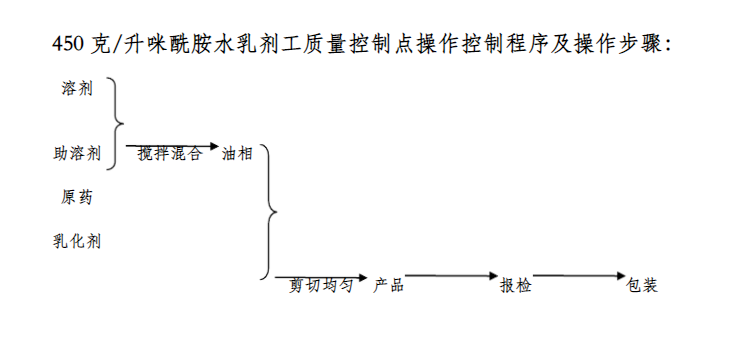
下载“百度文库”“豆丁网”文档,仅支持导出为txt文档或图片型的pdf。
当前为 2021-11-26 提交的版本,查看 最新版本。
您需要先安装一个扩展,例如 篡改猴、Greasemonkey 或 暴力猴,之后才能安装此脚本。
You will need to install an extension such as Tampermonkey to install this script.
您需要先安装一个扩展,例如 篡改猴 或 暴力猴,之后才能安装此脚本。
您需要先安装一个扩展,例如 篡改猴 或 Userscripts ,之后才能安装此脚本。
您需要先安装一款用户脚本管理器扩展,例如 Tampermonkey,才能安装此脚本。
您需要先安装用户脚本管理器扩展后才能安装此脚本。
(我已经安装了用户脚本管理器,让我安装!)
您需要先安装一款用户样式管理器扩展,比如 Stylus,才能安装此样式。
您需要先安装一款用户样式管理器扩展后才能安装此样式。
(我已经安装了用户样式管理器,让我安装!)
下载百度文库的文档,包括
对豆丁网文档的简单支持:以图片的形式保存为pdf文件(即使原文档是文字的而非扫描的图片)