通用网站内容抓取工具,可批量抓取小说、论坛内容等并保存为TXT文档
当前为




起点晋江红袖以及其他知名小说站都推荐用这个脚本【小说】下载脚本,遇到没人愿意适配的不知名小站再考虑我的脚本。
轻量级抓取脚本,用于下载网页中的主要内容,理论上适用于任何非Ajax写入正文的小说网站、论坛、贴吧等而无需为此写任何规则。
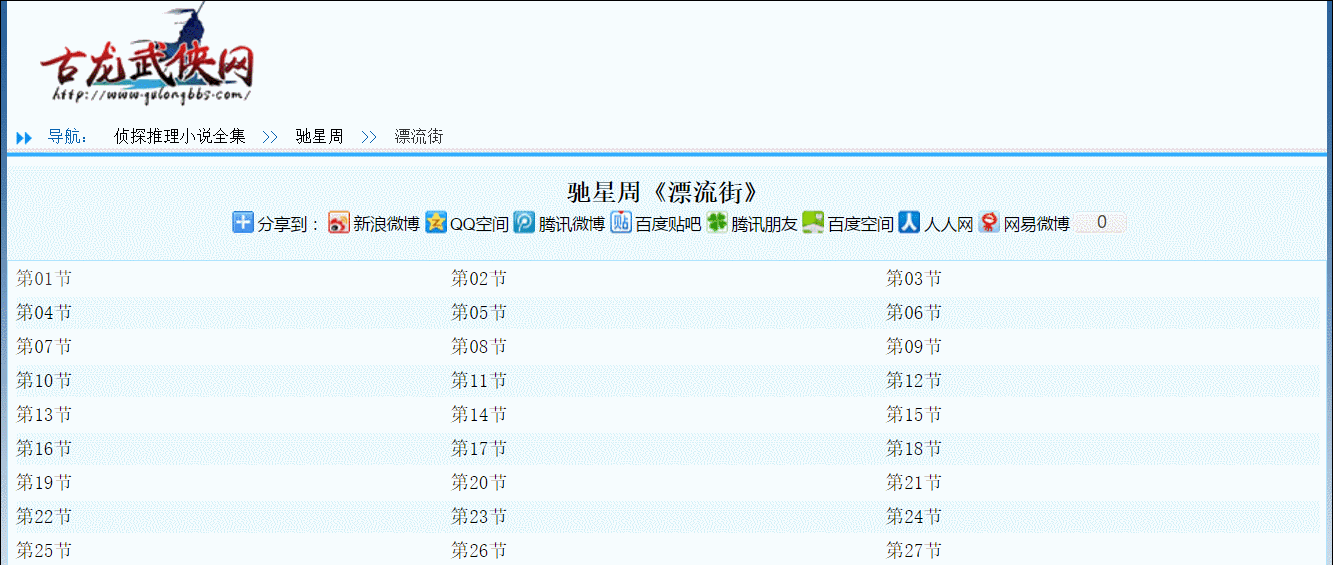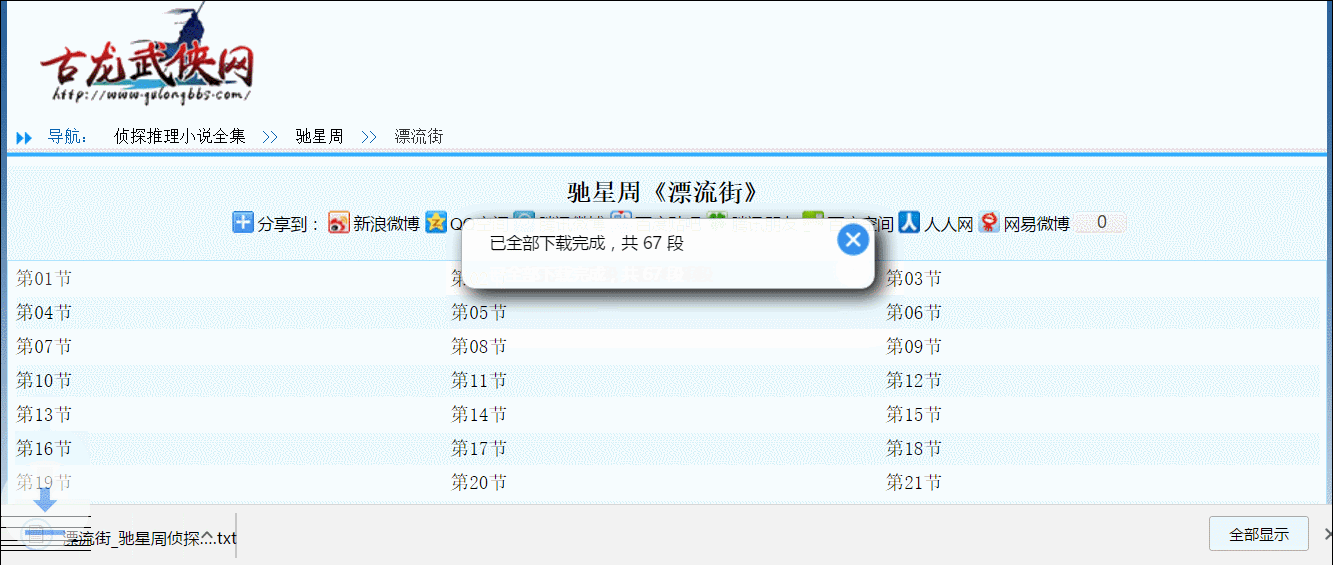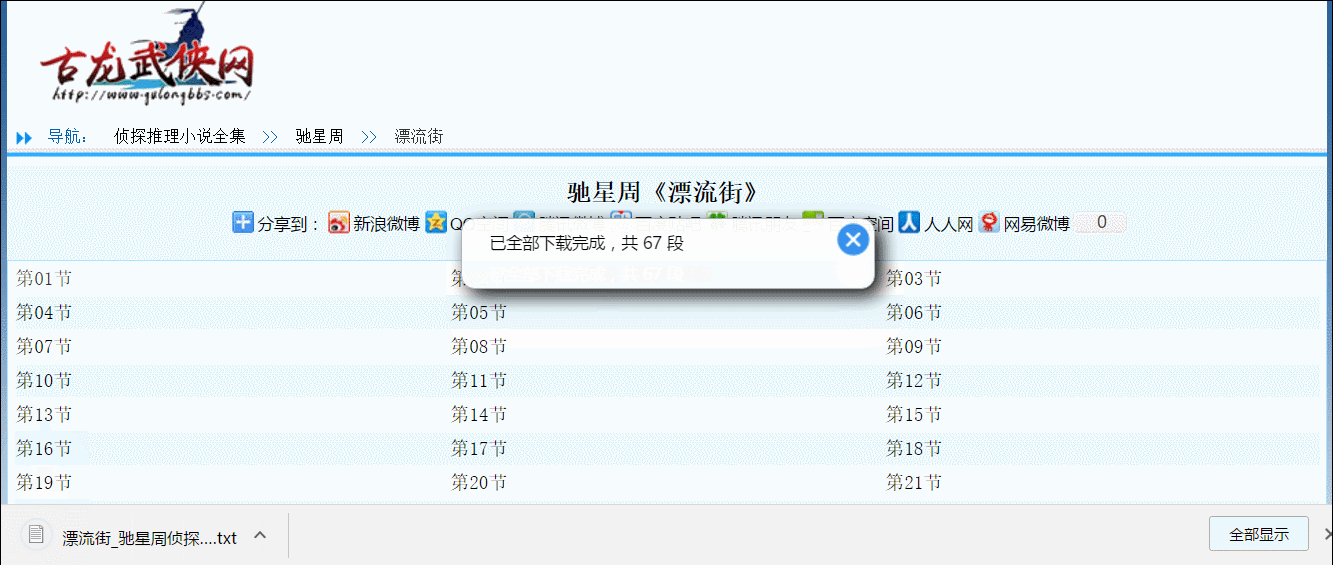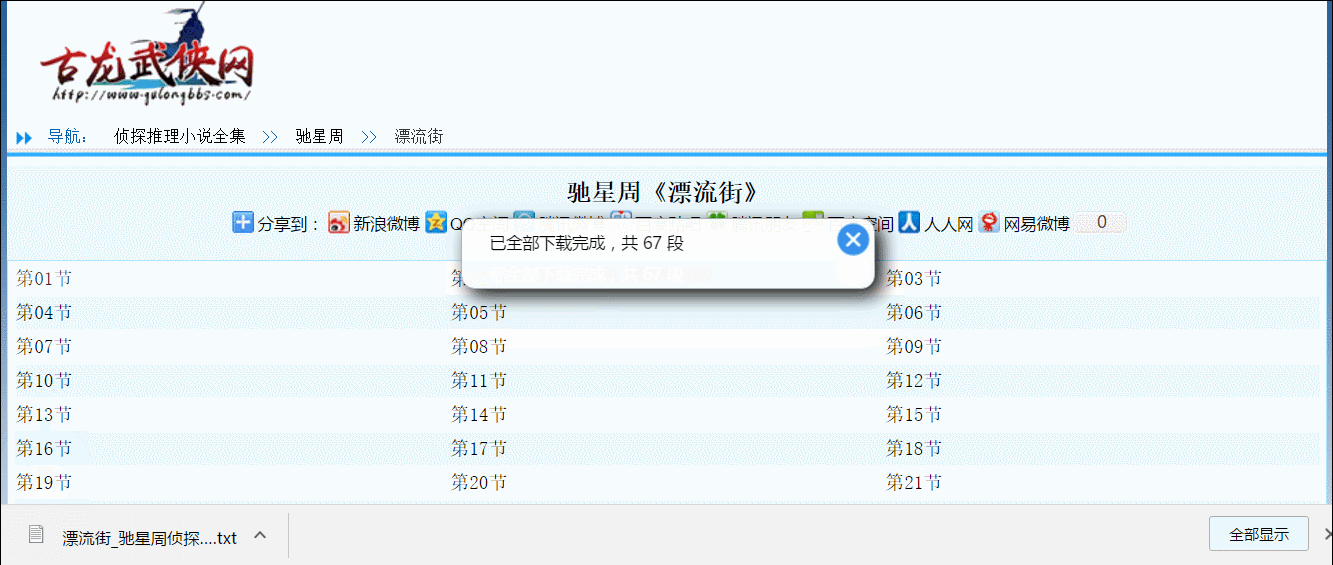
脚本会自动检索页面中的主要内容并下载(省得复制完gal攻略还要手动逐条删除“某某某13级头衔水龙王发表于X年X月X日来自XX客户端”)。 如果位于小说目录页会遍历所有章节并排序拼接后存为TXT文档。

CTRL+F9 或点击命令菜单SHIFT+CTRL+F9 忽略目录,仅下载当前页.mask,.ksam,意为删除class为mask或者ksam的元素。.l_chaptname>a ,输入并下载后发现通过 url 无法下载正文内容,正文是 ajax 通过 articlescontent 下载的。此时可后接 @@articles@@articlescontent (@@ 分隔) 将章节 url 中的 articles 替换为 articlescontent 。 综上 【.l_chaptname>a@@articles@@articlescontent】 可适配该站,粘贴进命令菜单即可下载。其中第一个 articles 可使用正则,例如 @@articles(\d+)@@$1content 代表将链接中的「articles1」「articles2」等替换为「1content」「2content」。main>section ul>li>div>a,无需替换链接,因此后两项留空。有6个@了 😂。正文在meta里,需要自定义代码提取meta-preload数据的content项。综上 【main>section ul>li>div>a@@@@@@var noval=JSON.parse(data.querySelector("#meta-preload-data").content).novel;noval[Object.keys(noval)[0]].content;】 即可下载p站小说。其中 "data" 代表抓取网页的document对象,若返回的是纯文本,则用 data.body.innerText 获取。如果有帮助到你,请杯奶茶吧,帮提神并鼓励常更新

主要是
 因为我要下载驰星周的漂流街,却发现前人的轮子“【小说】下载脚本”不能用,又不想为这破站 🙃 写规则,而且
因为我要下载驰星周的漂流街,却发现前人的轮子“【小说】下载脚本”不能用,又不想为这破站 🙃 写规则,而且我就是看不上霸道总裁修仙穿越你咬我啊指不定它三天两头改个版呢。写个通用规则的脚本,一来可以不用追着数不清的小说站适配修改更新,二来也免去了法律风险。
这个脚本会自动去查找主要内容并下载,不需要写规则。当然如果你家网站广告内容比正文还多我也没办法。
遇到特殊网站还是建议用“【小说】下载脚本”。